
Abstract
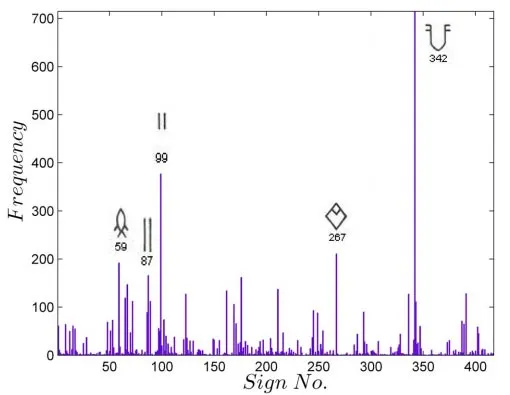
The Indus script is one of the major undeciphered scripts of the ancient world. The small size of the corpus, the absence of bilingual texts, and the lack of definite knowledge of the underlying language has frustrated efforts at decipherment since the discovery of the remains of the Indus civilization. Building on previous statistical approaches, we apply the tools of statistical language processing, specifically n-gram Markov chains, to analyze the syntax of the Indus script. We find that unigrams follow a Zipf-Mandelbrot distribution. Text beginner and ender distributions are unequal, providing internal evidence for syntax. We see clear evidence of strong bigram correlations and extract significant pairs and triplets using a log-likelihood measure of association. Highly frequent pairs and triplets are not always highly significant. The model performance is evaluated using information-theoretic measures and cross-validation. The model can restore doubtfully read texts with an accuracy of about 75%. We find that a quadrigram Markov chain saturates information theoretic measures against a held-out corpus. Our work forms the basis for the development of a stochastic grammar which may be used to explore the syntax of the Indus script in greater detail.
Statistical_Analysis-of_Indus-Script.pdf
(2.11 MB)
- Log in to post comments